
Posted on: November 12, 2019
Editor’s note: This blog post is the first in an ongoing series entitled “Technically Speaking.” In these posts, we write in a way that is understandable about very technical principles that we use in reading research. We want to improve busy practitioners’ and family members’ abilities to be good consumers of reading research and to deepen their understanding of how our research operates to provide the best information.
When conducting a study that attempts to measure the effectiveness of a reading intervention on student outcomes, there are two important goals of the researcher and the education stakeholders:
- Be able to generalize results to a wider student population
- Establish a causal relationship between the reading intervention and changes observed in student reading
Two essential principles related to the study’s design that help toward reaching those goals are random sampling and random assignment. In this part one post, we will focus on random sampling, which helps accomplish the first goal. A part two post on random assignment, which helps accomplish the second goal, will come soon after.
Generalizing to a Wider Student Population with Random Sampling
When conducting reading research, we must first define our population of interest, or the universe of students for whom we want to learn more about the way they read. Are conclusions being drawn about all third graders in the district? Third graders in the district who are struggling readers? Third graders only within the school where the study is conducted? We will be generalizing any conclusions about these students we may draw from our study.
Once a population of interest is defined, how do we know that our sample of students participating in the study is representative of that population? When feasible, statisticians select a sampling approach. Sampling involves selecting units from a population of interest such that the sampling units represent the whole population. Within the context of studying reading interventions within schools, the unit being sampled can range from a number of students within a classroom to entire classrooms or schools, or even a combination of these units. Random sampling is one such procedure that selects a sample of units from a population by chance, typically to facilitate generalization from the sample to the population (Shadish, Cook, & Campbell, 2002). Random sampling ensures that results obtained from your sample should approximate what would have been obtained if the entire population had been measured (Shadish et al., 2002). The simplest random sample allows all the units in the population to have an equal chance of being selected. Often in practice we rely on more complex sampling techniques.
The phrase by chance in the definition for random sampling is what distinguishes it from many other sampling procedures. In many intervention studies, for instance, a convenience sample is chosen—schools are selected that have the infrastructure and time to partake in the study, or certain teachers within the school are selected because they are willing or able to have their students participate in the study. Likewise, a purposive sample may be chosen. For example, administrators volunteer their highest-quality teachers to participate because they feel it increases the chances that the reading intervention will be found to be successful. In each of these cases, the type of sampling used is not random by definition, because not every teacher or school in the population has an equal chance of being selected to participate. Thus, the ability to generalize results from such studies to a larger population (known as the external validity of the study) can be compromised.
Perhaps the most important benefit to selecting random samples is that it enables the researcher to rely upon assumptions of statistical theory to draw conclusions from what is observed (Moore & McCabe, 2003). For example, if data are produced by random sampling, any statistics generated from the data can be assumed to follow a specific distribution. The distribution with which many educators are most familiar is the normal distribution of a bell-shaped curve. In this distribution, most of the students’ data would fall in the middle, or the average range of performance, and fewer students’ data would fall in the very high or very low performance ranges on either side of the middle. This provides the researcher a better understanding of how the results from the sample relate to what the results would be for the whole population. Quantifying the degree to which we can confidently know how sample results relate to the population is key to drawing sound inferences and generalizing those results to the student population.
Of course, even within the context of random sampling, several other factors influence a reading study’s external validity. For example, there is the role of sample size to consider. Larger random samples will typically produce more stable results, meaning estimates for the effect the intervention had on student outcomes can be obtained with smaller margins of error. There is often a balance the school researcher must consider: obtaining large enough samples to adequately represent the population and achieve reliable results while also working within the financial and logistical constraints of conducting the study.
An Example of Random Sampling in Reading Research
Assume that Figure 1 below displays our student population of interest, and the colored dots represent students with different characteristics.
Figure 1. Hypothetical Population

Figure 2 is a simple random sample of 100 students from the population of interest (i.e., from Figure 1).
Figure 2. Random Sample
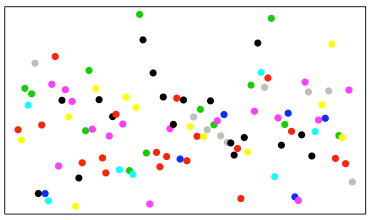
Simple random sampling does not guarantee that all important student characteristics are represented in the sample. If the student characteristics represented by the distinct colors are something believed to be of importance when designing the study, typically we will separate the sample into groups based on those characteristics (a process referred to as stratifying the sample) and then sample units from those groups or strata. This is done to ensure that all characteristics are properly represented.
For sound inferences to be drawn from reading intervention studies, researchers need to be able to generalize results from their student samples to a wider student population of interest. An essential principle for making that generalization is integrating random sampling of students or classrooms into the study design. In an upcoming part two post, we will discuss the importance of randomly assigning students to study conditions if we want to make sound causal inferences about reading interventions.
References
Moore, D. S., & McCabe, G. P. (2003). Introduction to the practice of statistics (4th ed.). WH Freeman: New York, NY.
Shadish, W. R., Cook, T. D., & Campbell, D. T. (2002). Experimental and quasi-experimental designs for generalized causal inference. Cengage Learning: Boston, MA.